Migrating from SQL to No-SQL without downtime
Recently, we migrated a large MySQL database containing GB’s of data, millions of rows in few tables to CosmosDB.
This was done without downtime. I want to lay down the approach we took in this post.
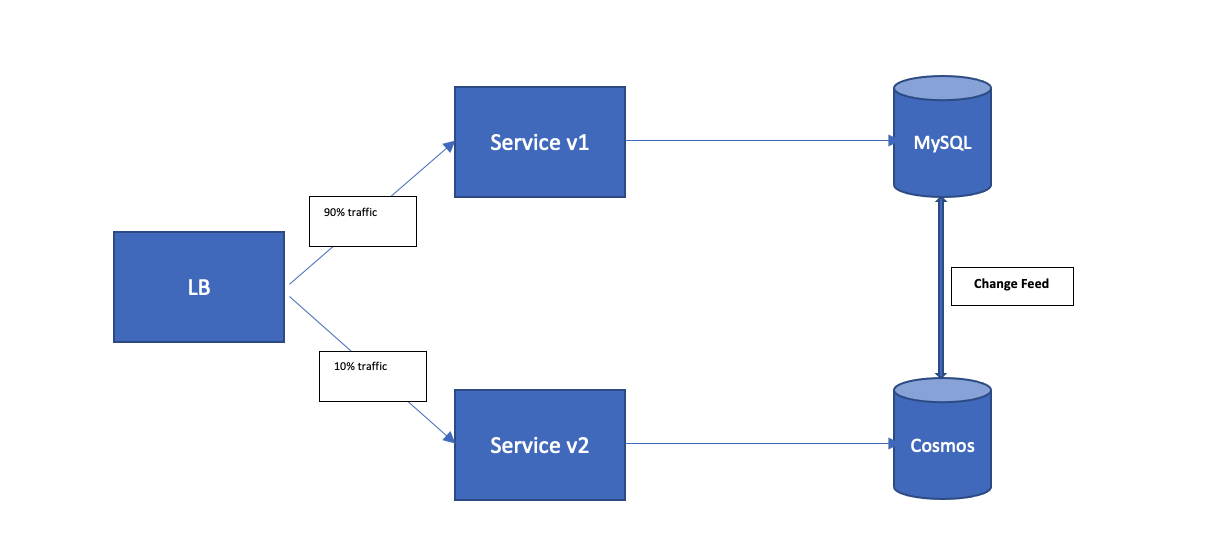
Our intention was to setup both the database active - active and incrementally shift the traffic point to Service v1 (which was reading/writing to MySQL) towards Service v2 (which was reading/writing to CosmosDB)
The first challenge was doing the initial data migration (called as bootstrap) and then set up a replication pipeline (called as change feed) so that any updates/inserts/deletes happening on live MySQL DB are replicated to CosmosDB asynchronously.
For this, we made use of Kafka.
-
The Bootstrap process consisted of reading the table from MySQL and dumping its content into a corresponding Kafka topic. That means, we had a corresponding Kafka topic for each table within MySQL. There are products within market such as this which can do this as well.
-
The change feed process consisted of having another set of parallel kafka topics which would contain the change feed, i.e. inserts / deletes / updates happening on the MySQL database. This was tricky because setting it up requires modifying the service layer to publish this feeds to Kafka.
The point to note above is that bootstrap is a one time process and Change feed is an ongoing process. Also, bootstrap must be executed after the change feed process is up and running, so as to not miss any record.
Now comes the consumer part, The consumer application will connect to these kafka topics and store the data in Cosmos DB. We used bulk insertion in batches of 4000 records/batch to speed up the insertions.
Here, the bootstrap kafka topics must be first completely consumed and written to target database before starting with ChangeFeed kafka topics.
As the change feed kafka topics lag becomes closer to zero (it will never be zero, since data is always being written to change feed topics), the databases are considered active active.
Few notes about Kafka:
-
Use Kafka partitions to scale up bootstrap and consumption process horizontally. The partition key can be primary key of the table. This is especially important in change feed topics where multiple records will exist for same row.
-
The consumer application must handle errors gracefully. If there is an error during the batch writes, the entire batch might fail.
-
Use the blue green deployment methodology
In our case, it took almost 4 hrs to complete the migration including bootstrap and change feed process for around 3 million rows in couple of tables and fewer records in other tables.